In May 2013, the mathematician Yitang Zhang launched what has proven to be a banner year and a half for the study of prime numbers, those numbers that aren’t divisible by any smaller number except 1. Zhang, of the University of New Hampshire, showed for the first time that even though primes get increasingly rare as you go further out along the number line, you will never stop finding pairs of primes that are a bounded distance apart — within 70 million, he proved. Dozens of mathematicians then put their heads together to improve on Zhang’s 70 million bound, bringing it down to 246 — within striking range of the celebrated twin primes conjecture, which posits that there are infinitely many pairs of primes that differ by only 2.
Now, mathematicians have made the first substantial progress in 76 years on the reverse question: How far apart can consecutive primes be? The average spacing between primes approaches infinity as you travel up the number line, but in any finite list of numbers, the biggest prime gap could be much larger than the average. No one has been able to establish how large these gaps can be.
“It’s a very obvious question, one of the first you might ever ask about primes,” said Andrew Granville, a number theorist at the University of Montreal. “But the answer has been more or less stuck for almost 80 years.”
This past August, two different groups of mathematicians released papers proving a long-standing conjecture by the mathematician Paul Erdős about how large prime gaps can get. The two teams have joined forces to strengthen their result on the spacing of primes still further, and expect to release a new paper later this month.
Erdős, who was one of the most prolific mathematicians of the 20th century, came up with hundreds of mathematics problems over his lifetime, and had a penchant for offering cash prizes for their solutions. Though these prizes were typically just $25, Erdős (“somewhat rashly,” as he later wrote) offered a $10,000 prize for the solution to his prime gaps conjecture — by far the largest prize he ever offered.
Erdős’ conjecture is based on a bizarre-looking bound for large prime gaps devised in 1938 by the Scottish mathematician Robert Alexander Rankin. For big enough numbers X, Rankin showed, the largest prime gap below X is at least
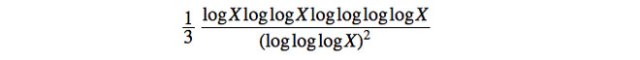
Number theory formulas are notorious for having many “logs” (short for the natural logarithm), said Terence Tao of the University of California, Los Angeles, who wrote one of the two new papers along with Kevin Ford of the University of Illinois, Urbana-Champaign, Ben Green of the University of Oxford and Sergei Konyagin of the Steklov Mathematical Institute in Moscow. In fact, number theorists have a favorite joke, Tao said: What does a drowning number theorist say? “Log log log log … ”
Nevertheless, Rankin’s result is “a ridiculous formula, that you would never expect to show up naturally,” Tao said. “Everyone thought it would be improved on quickly, because it’s just so weird.” But Rankin’s formula resisted all but the most minor improvements for more than seven decades.
Many mathematicians believe that the true size of large prime gaps is probably considerably larger — more on the order of (log X)2, an idea first put forth by the Swedish mathematician Harald Cramér in 1936. Gaps of size (log X)2 are what would occur if the prime numbers behaved like a collection of random numbers, which in many respects they appear to do. But no one can come close to proving Cramér’s conjecture, Tao said. “We just don’t understand prime numbers very well.”
Erdős made a more modest conjecture: It should be possible, he said, to replace the 1/3 in Rankin’s formula by as large a number as you like, provided you go out far enough along the number line. That would mean that prime gaps can get much larger than in Rankin’s formula, though still smaller than in Cramér’s.
The two new proofs of Erdős’ conjecture are both based on a simple way to construct large prime gaps. A large prime gap is the same thing as a long list of non-prime, or “composite,” numbers between two prime numbers. Here’s one easy way to construct a list of, say, 100 composite numbers in a row: Start with the numbers 2, 3, 4, … , 101, and add to each of these the number 101 factorial (the product of the first 101 numbers, written 101!). The list then becomes 101! + 2, 101! + 3, 101! + 4, … , 101! + 101. Since 101! is divisible by all the numbers from 2 to 101, each of the numbers in the new list is composite: 101! + 2 is divisible by 2, 101! + 3 is divisible by 3, and so on. “All the proofs about large prime gaps use only slight variations on this high school construction,” said James Maynard of Oxford, who wrote the second of the two papers.
The composite numbers in the above list are enormous, since 101! has 160 digits. To improve on Rankin’s formula, mathematicians had to show that lists of composite numbers appear much earlier in the number line — that it’s possible to add a much smaller number to a list such as 2, 3, … , 101 and again get only composite numbers. Both teams did this by exploiting recent results — different ones in each case — about patterns in the spacing of prime numbers. In a nice twist, Maynard’s paper used tools that he developed last year to understand small gaps between primes.
The five researchers have now joined together to refine their new bound, and plan to release a preprint within a week or two which, Tao feels, pushes Rankin’s basic method as far as possible using currently available techniques.
The new work has no immediate applications, although understanding large prime gaps could ultimately have implications for cryptography algorithms. If there turn out to be longer prime-free stretches of numbers than even Cramér’s conjecture predicts, that could, in principle, spell trouble for cryptography algorithms that depend on finding large prime numbers, Maynard said. “If they got unlucky and started testing for primes at the beginning of a huge gap, the algorithm would take a very long time to run.”
Tao has a more personal motivation for studying prime gaps. “After a while, these things taunt you,” he said. “You’re supposed to be an expert on prime numbers, but there are these basic questions you can’t answer, even though people have thought about them for centuries.”
Erdős died in 1996, but Ronald Graham, a mathematician at the University of California, San Diego, who collaborated extensively with Erdős, has offered to make good on the $10,000 prize. Tao is toying with the idea of creating a new prize for anyone who makes a big enough improvement on the latest result, he said.
In 1985, Tao, then a 10-year-old prodigy, met Erdős at a math event. “He treated me as an equal,” recalled Tao, who in 2006 won a Fields Medal, widely seen as the highest honor in mathematics. “He talked very serious mathematics to me.” This is the first Erdős prize problem Tao has been able to solve, he said. “So that’s kind of cool.”
The recent progress in understanding both small and large prime gaps has spawned a generation of number theorists who feel that anything is possible, Granville said. “Back when I was growing up mathematically, we thought there were these eternal questions that we wouldn’t see answered until another era,” he said. “But I think attitudes have changed in the last year or two. There are a lot of young people who are much more ambitious than in the past, because they’ve seen that you can make massive breakthroughs.”
http://www.wired.com/2014/12/mathematicians-make-major-discovery-prime-numbers/?mbid=social_fb