By Edd Gent
The idea of a machine that can decode your thoughts might sound creepy, but for thousands of people who have lost the ability to speak due to disease or disability it could be game-changing. Even for the able-bodied, being able to type out an email by just thinking or sending commands to your digital assistant telepathically could be hugely useful.
That vision may have come a step closer after researchers at the University of California, San Francisco demonstrated that they could translate brain signals into complete sentences with error rates as low as three percent, which is below the threshold for professional speech transcription.
While we’ve been able to decode parts of speech from brain signals for around a decade, so far most of the solutions have been a long way from consistently translating intelligible sentences. Last year, researchers used a novel approach that achieved some of the best results so far by using brain signals to animate a simulated vocal tract, but only 70 percent of the words were intelligible.
The key to the improved performance achieved by the authors of the new paper in Nature Neuroscience was their realization that there were strong parallels between translating brain signals to text and machine translation between languages using neural networks, which is now highly accurate for many languages.
While most efforts to decode brain signals have focused on identifying neural activity that corresponds to particular phonemes—the distinct chunks of sound that make up words—the researchers decided to mimic machine translation, where the entire sentence is translated at once. This has proven a powerful approach; as certain words are always more likely to appear close together, the system can rely on context to fill in any gaps.
The team used the same encoder-decoder approach commonly used for machine translation, in which one neural network analyzes the input signal—normally text, but in this case brain signals—to create a representation of the data, and then a second neural network translates this into the target language.
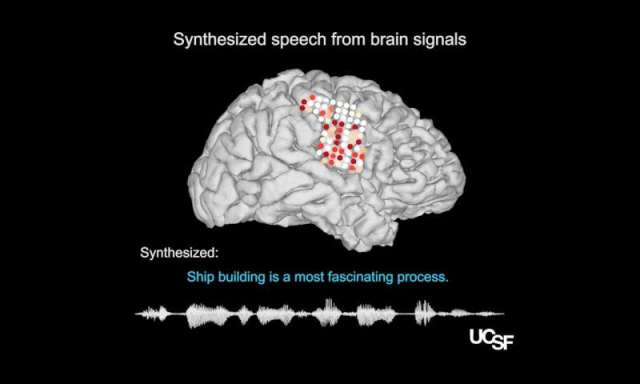
They trained their system using brain activity recorded from 4 women with electrodes implanted in their brains to monitor seizures as they read out a set of 50 sentences, including 250 unique words. This allowed the first network to work out what neural activity correlated with which parts of speech.
In testing, it relied only on the neural signals and was able to achieve error rates of below eight percent on two out of the four subjects, which matches the kinds of accuracy achieved by professional transcribers.
Inevitably, there are caveats. Firstly, the system was only able to decode 30-50 specific sentences using a limited vocabulary of 250 words. It also requires people to have electrodes implanted in their brains, which is currently only permitted for a limited number of highly specific medical reasons. However, there are a number of signs that this direction holds considerable promise.
One concern was that because the system was being tested on sentences that were included in its training data, it might simply be learning to match specific sentences to specific neural signatures. That would suggest it wasn’t really learning the constituent parts of speech, which would make it harder to generalize to unfamiliar sentences.
But when the researchers added another set of recordings to the training data that were not included in testing, it reduced error rates significantly, suggesting that the system is learning sub-sentence information like words.
They also found that pre-training the system on data from the volunteer that achieved the highest accuracy before training on data from one of the worst performers significantly reduced error rates. This suggests that in practical applications, much of the training could be done before the system is given to the end user, and they would only have to fine-tune it to the quirks of their brain signals.
The vocabulary of such a system is likely to improve considerably as people build upon this approach—but even a limited palette of 250 words could be incredibly useful to a paraplegic, and could likely be tailored to a specific set of commands for telepathic control of other devices.
Now the ball is back in the court of the scrum of companies racing to develop the first practical neural interfaces.
How a New AI Translated Brain Activity to Speech With 97 Percent Accuracy